AWS Redshift is a big data storage (“data warehousing”) solution for analytics. Based on PostgreSQL 8, it can combine up to 128 largest nodes, giving you 2 petabytes for your data. Well, almost. You don’t get ALL that for your data.

What’s not commonly known about Redshift, is the details on how its storage works and how space is allocated across nodes in a multi-node cluster. In very simple terms, storage space on nodes is additive, meaning: more nodes, more space. For most people, that would mean that in a cluster of 2 dc1.large nodes (160GB of storage each), they should have 320GB of storage available for their data. Adding 2 more nodes, would bring the space to 640GB and so on. But that’s not really how it works.
Redshift has a notion of “minimum table size” - which is a minimal amount of space that’s allocated for each table you create (based on amount of columns in the table). That sounds fair, right? Metadata and whatnot, has to live somewhere. The problem appears, when you realise that this space has to be allocated for your table on every node. And we’re not talking about megabytes, but gigabytes of space.
Recently, I’ve been working with a client that’s using a third-party Business intelligence (BI) software which uses
Redshift as data store. That software makes it very easy for users to create new tables, copy the data and run whatever
transformations on that data they need. My client had a Redshift cluster composed of two dc1.large nodes (which
theoretically gave them 320GB of storage). When working with their data, that space was quickly used up and they
requested another 2 nodes for their cluster. But, after the resize the available storage space reported… didn’t
double. Check out the graph from AWS console:
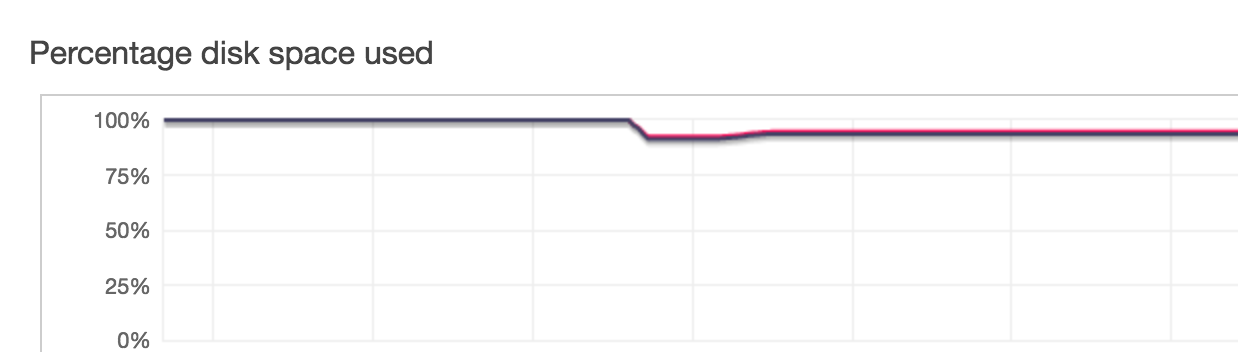
Used storage space went from 100% to ~92%. That’s definitely not what we were expecting when doubling the amount of nodes in the cluster! After a long conversation with AWS support, we were pointed to the minimum table size document: aws.amazon.com/premiumsupport/knowledge-center/redshift-cluster-storage-space/ . It turned out, that the 3rd party software created over 1660 tables inside the Redshift cluster - after adding up the minimum table size required for each of those (that has to be allocated on each node!), we ended up with almost no other storage left (after allocating the space for each table, each node ended up with only a couple of GB of free storage). The only real advice that we were given was to change the node type (so that we have more storage per node) - but if my client continues to use that software and create more and more tables as they go along, at some point we’ll end up with the biggest node (ds2.8xlarge) and the 16TB of storage it provides will not be enough. If we start adding more nodes, each of them will continue to only have a small % of free storage left, which will mean we’re wasting an incredible amount of very expensive storage space (ds2.8xlarge costs $7.60 per hour!).
It’s quite obvious that Redshift is simply not the right backend for this software solution, but it looks like some vendors use technologies simply for marketing (“we use this awesome new tech!”). We went back to the vendor with this information, but didn’t receive any feedback so far.


